


The tale...
Is Rust that scary? That's what I asked myself when I decided to learn this programming language that promises to be fast, safe and concurrent.
My friend, who has 15 years of back-end experience, said that I was nuts.
He said that Rust is too complex, too hard to master, and too unforgiving for beginners and that I would spend more time fighting with the compiler than writing actual code.
That's his opinion, but is he right?
Is Rust a nightmare for developers? Or is it a misunderstood gem that offers a unique way of thinking and solving problems?
In this and many of future articles, I will share with you my journey of learning Rust, the challenges I faced, and the benefits I gained. I will also give you some examples of things that scare most developers away from Rust, such as ownership, borrowing, lifetimes, and error handling. And I will show you how to overcome them with patience, practice, and perseverance.
This article will be a little bit general, where you'll not find a **Rust 101-**like cheat sheet and so on. It is going to be more introduction to the language and a teaser about what can you expect from the language and its ecosystem.
History of Rust
Rust was created by Graydon Hoare, a Mozilla employee, who started it as a personal project in 2006. He was inspired by languages like C++, Haskell, and OCaml, but wanted to avoid the memory bugs that plagued C and C++ code. Mozilla saw the potential of Rust and began sponsoring it in 2009, using it for its experimental browser engine, Servo. Rust was officially announced to the public in 2010.
Since then, Rust has evolved through many versions, reaching its first stable release, Rust 1.0, in 2015. Rust has attracted a large and enthusiastic community of developers, who contribute to its open-source development and governance. Rust has also been adopted by many companies and organizations, such as Microsoft, Amazon, Dropbox, Cloudflare, and the US government, for various applications ranging from web services to operating systems.

Popularity
Rust has been consistently rated as the most loved programming language by developers on Stack Overflow for seven years in a row.
And wherever I look I see:
"Rust, write in Rust!"
Rust for data engineering!
Rust for back-end!
Rust for web assembly!
etc etc...
Seeing that hype everywhere must mean something, right?
The pros
As you probably already know, Rust is a statically compiled general-purpose and system-programming language built with memory safety, concurrency and security from the ground up.
It is incredibly fast, safe and less error-prone than e.g. Golang or Scala. Rust's incredible compiler not only checks and compiles code - it is a tutor, a teacher.
In other means, it does not only show you an error itself but explains the reason behind it and gives you advice on what you should do to eliminate the error. In 99% of situations you even do not need to jump into the docs, because it constantly helps you during the inspection:
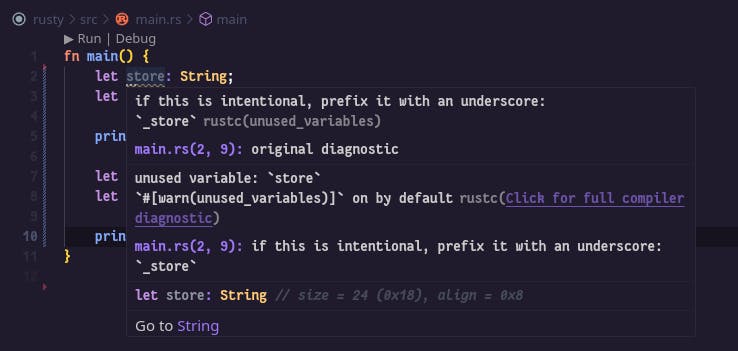
For some, it may be rather a trivial example, but for a DevOps Engineer who worked with interpreted Python and Ruby - the level of inspection is great and allows me to eliminate 99.9% of errors before they occur.
The so-called built-in the teacher inside the compiler mentioned earlier is another example of how Rust shines above other languages.
Look at this simple example of an error:
--> src/main.rs:3:5
|
2 | let store = "Walmart";
| -----
| |
| first assignment to `store`
| help: consider making this binding mutable: `mut store`
3 | store = "MediaExpert";
| ^^^^^^^^^^^^^^^^^^^^^ cannot assign twice to immutable variable
For more information about this error, try `rustc --explain E0384`.
warning: `rusty` (bin "rusty") generated 1 warning
error: could not compile `rusty` due to previous error; 1 warning emitted
As you can see in the output, it even explains what happened, giving and pointing an error in the code and how it can be fixed.
Additionally, it gives us a snippet that can be invoked from Shell for further explanation:
rustc --explain E0384
An immutable variable was reassigned.
Erroneous code example:
fn main() { let x = 3; x = 5; // error, reassignment of immutable variable }By default, variables in Rust are immutable. To fix this error, add the keyword
mutafter the keywordletwhen declaring the variable. For example:fn main() { let mut x = 3; x = 5; }
Isn't that great?
The docs
This is another great thing about Rust: the docs.
In my opinion, Rust has probably one of the best docs you could ever imagine.
Just take a look a those two:
Together with interactive exercises called Rustlings, you could probably never need additional books.

The bad ones
Of course, there are a few things that we can put into the cons list.
The main problem of Rust is that compilations are slow, really slow compared to Go for example.
Another thing is that there is a limited choice of compilers and target architectures compared to C/C++ or Go. Few third-party libraries for Rust are limited or immature and integrations with other languages can be unsafe or difficult (for some).
Integration with database engines could be a problem too. It has great support for MySQL, Postgres and SQLite. Whereas Oracle SQL Server or Microsft SQL Server is still in 'the works'. You should consider that you would probably need to write something on your own.
Still, it's not that bad for a language that had its public release thirteen years ago.
Installation
The best way to install Rust on unix-like OS is to use rustup from the official website:
COPY
curl --proto '=https' --tlsv1.2 -sSf https://sh.rustup.rs | sh
For future updates, you can use:
rustup update
For the sake of happiness, add this to your .bashrc or .zshrc:
# Rust
export PATH=$HOME/.cargo/bin:$PATH
Starting you journey
To start writing your code, navigate to the directory where you want to store the code:
cd ~/repos && cargo new rusty
Where rusty is your pet code directory.
Data types
Rust has a few data types, but not as many as Scala (collection types):
| Data Type | Description |
bool | A boolean value (true or false) |
char | A Unicode character |
i8, i16, i32, i64, i128 | Signed integers with various bit widths |
u8, u16, u32, u64, u128 | Unsigned integers with various bit widths |
isize, usize | Signed and unsigned integers that are the same size as a pointer |
f32, f64 | Floating-point numbers with single and double precision |
array | A fixed-size array of elements of the same type |
slice | A dynamically sized view into a contiguous sequence of elements of the same type |
str | A string slice (&str) or an owned string (String) |
tuple | A fixed-size collection of elements of different types |
struct | A custom data type that groups together named or unnamed fields of different types |
enum | A custom data type that can have one of several variants, each with its own data type or no data at all |
option | A type that represents either a value or nothing (Some(value) or None) |
result | A type that represents either a successful value (Ok(value)) or an error (Err(error)) |
vector | A dynamically sized collection of elements of the same type that can grow or shrink as needed |

How about syntax?
Basics
As in C/C++ or Go, the code is run from the main function:
fn main() {
println!("Hi")
}
To declare the variable we use the keyword let:
let store; // declaration
store = "Walmart" // assign "Walmart" to 'store'
println!("I went to {}!", store); // I went to Walmart!
To make a variable mutable, we use mut keyword:
let mut store;
store = "Walmart"
println!("I went to {}!", store); // I went to Walmart!
store = "MediaExpert";
println!("I went to {}!", store); // I went to MediaExpert!
And this is one of the things that you will have to take care of in future.
Functions
As you probably already noticed, functions are defined using fn keyword:
fn fibonacci(n: u32) -> u32 {
if n == 0 || n == 1 {
return n;
}
fibonacci(n - 1) + fibonacci(n - 2)
}
fn main() {
println!("fibonacci(10) = {}", fibonacci(10));
}
Control flow
As you saw above, control flow in Rust is not much different than in other languages:
fn main() {
let r = vec![1231, 6, 23, 4, 555];
if r.iter().any(|&x| x == 555) {
println!("Yes");
}
let anwser = if r.iter().any(|&x| x == 3) {
"Yes"
} else {
"No"
};
let mut v = vec![1, 2, 3, 4, 5];
let third: &i32 = &v[2];
println!("The third element is {}", third);
&v.push(6);
for ele in &v {
println!("{}", ele);
}
for ele in &mut v {
*ele += 50;
}
for ele in &v {
println!("{}", ele);
}
for x in 1..10 {
println!("{}", x);
}
for y in (660..=666).rev() {
println!("{}", y);
}
let r = vec![1, 2, 3, 4, 5];
let mut index = 0;
while index < 5 {
println!("The value is: {}", r[index]);
index += 1;
}
}
Structs, methods and traits
Structs are custom data types that group together named or unnamed fields of different types. Structs are similar to classes in other programming languages.
Methods are functions that are associated with a particular struct or enum. They are similar to instance methods in other languages, but the same as structs, with some differences.
In Rust, traits are a way to define shared behavior between different types. They are similar to interfaces in other programming languages but with some important differences.
A trait defines a set of methods that a type must implement to be considered "compatible" with the trait. Types that implement a trait are said to "implement" the trait and can be used in any context that expects a value of that trait.
Here's an example of a trait definition in Rust:
trait Engine {
fn start(&self);
fn stop(&self);
}
In this example, we define a trait called Engine that has two methods: start and stop. Any type that implements these methods can be considered an Engine, regardless of its specific implementation.
Here's an example of how to implement a trait for a type in Rust:
struct GasolineEngine {
cylinders: u32,
horsepower: u32,
}
impl Engine for GasolineEngine {
fn start(&self) {
println!("Starting gasoline engine with {} cylinders and {} horsepower", self.cylinders, self.horsepower);
}
fn stop(&self) {
println!("Stopping gasoline engine");
}
}
In this example, we define a struct called GasolineEngine that has two fields: cylinders and horsepower. Then we implement the Engine trait for GasolineEngine by defining the start and stop methods. Any value of type GasolineEngine can now be used in any context that expects an Engine.
Next, we do the same for an electric engine:
struct ElectricEngine {
kilowatt_hours: u32,
}
impl Engine for ElectricEngine {
fn start(&self) {
println!(
"Starting electric engine with {} kilowatt hours",
self.kilowatt_hours
);
}
fn stop(&self) {
println!("Stopping electric engine");
}
}
Then we create the struct for Car and implement Engine trait:
struct Car<E: Engine> {
engine: E,
}
impl<E: Engine> Car<E> {
fn new(engine: E) -> Car<E> {
Car { engine: engine }
}
fn start(&self) {
self.engine.start();
}
fn stop(&self) {
self.engine.stop();
}
}
Now the main function ends like this:
fn main() {
let gasoline_car = Car::new(GasolineEngine {
cylinders: 4,
horsepower: 200,
});
gasoline_car.start();
gasoline_car.stop();
let electric_car = Car::new(ElectricEngine { kilowatt_hours: 60 });
electric_car.start();
electric_car.stop();
}
Result:
Starting gasoline engine with 4 cylinders and 200 horsepower
Stopping gasoline engine
Starting electric engine with 60 kilowatt hours
Stopping electric engine
As you can see: structs, methods and traits are powerful tools for defining shared behavior in Rust, and they are used extensively in many Rust programs.
Why do we have two types of string?
In Rust, String and &str are both used to represent text, but they have different ownership and borrowing semantics.
String is a growable, heap-allocated data structure that owns its contents. It is used when you need to modify or own the contents of a string. You can create a String from a string literal using the to_string method or the String::from function.
&str is a string slice that points to a sequence of UTF-8 bytes, usually stored elsewhere in memory. It is used when you need to borrow a string without taking ownership of it. You can create a string slice from a string literal using the & operator or the as_str method.
Here's an example that demonstrates the difference between String and &str:
fn main() {
let s1 = String::from("hello");
let s2 = "world";
let s3 = s1 + s2; // s1 is moved and can no longer be used
println!("s3 = {}", s3);
let s4 = "hello".to_string();
let s5 = s4.as_str();
println!("s4 = {}, s5 = {}", s4, s5);
}
In this example, s1 is a String that is concatenated with s2, which is a string slice. The result is a new String called s3. Because s1 is moved during the concatenation, it can no longer be used afterwards.
s4 is a String created from a string literal using the to_string method. s5 is a string slice that borrows the contents of s4 using the as_str method. Because s5 is a reference to s4, it does not take ownership of the string and s4 can still be used afterwards.
Pointers and references in Rust
In Rust, references and pointers are both used to refer to values without taking ownership of them, but they have different syntax and semantics.
A reference is a pointer that is guaranteed to be valid and non-null. References are created using the & operator and can be either immutable (&T) or mutable (&mut T). They are used to borrow a value without taking ownership of it, and they can be dereferenced using the * operator.
A pointer, on the other hand, is a raw memory address that may or may not be valid or null. Pointers are created using the *const T or *mut T syntax and are used to represent raw memory addresses. They are used when interacting with C code or when working with low-level memory operations.
Here's an example that demonstrates the difference between a reference and a pointer:
fn main() {
let x = 42;
let y = &x as *const i32;
println!("x = {}", x);
unsafe {
println!("y = {}", *y);
}
}
In this example, we create a variable x with the value 42. We then create a reference y to x using the & operator and cast it to a raw pointer using the as keyword. We then print the values of x and y to the console. Because y is a raw pointer, we need to use the unsafe keyword and the * operator to dereference it and access its value.
References are a safer and more idiomatic way to borrow values in Rust, and they are used extensively in Rust code. Pointers are used less frequently, but they are still useful for certain low-level operations.

The ownership and borrowing
Rust has no garbage collector like for example Go, Python and Ruby. Once the object stored on the heap goes out of scope - it is dropped:
fn main() {
let v = vec![1, 2, 3, 4, 5];
println!("The vector is {:?}", v);
} // v goes out of scope and is dropped here
In Rust, ownership and borrowing is a way to manage memory by allowing multiple parts of the code to access the same data without copying it.
Instead of manual memory management like in C/C++ - Rust does it differently and interestingly.
To make it as short as it can be:
When a variable is borrowed, it means that another part of the code can use it, but the original owner still retains ownership. This helps prevent memory leaks and other issues that can arise from multiple parts of the code trying to modify the same data at the same time. Rust's ownership rules ensure that the code is safe and prevent common programming errors.
Here's an example of how you can modify the code to use a reference instead of a value:
fn main() {
let store = "Walmart";
println!("I went to {}", store);
print_store(&store);
}
fn print_store(store: &str) {
println!("The store is {}", store);
}
In this modified code, we pass a reference to the store variable to the print_store function using the & symbol. This allows us to avoid copying the value of store and instead pass a pointer to its memory location. The print_store function then uses the reference to access the value of store without taking ownership of it. This is an example of Rust's borrowship in action.
In other words, ownership and borrowing rules are used to manage memory safety and prevent common programming errors such as null pointer dereferences and use-after-free bugs. Here are the key rules:
Each value in Rust has a variable that is its owner.
There can only be one owner at a time.
When the owner goes out of scope, the value will be dropped.
You can borrow a reference to a value without taking ownership.
You can have either one mutable reference or any number of immutable references to a value at a time.
References must always be valid and non-null.
These rules ensure that Rust code is safe and free from common memory-related bugs. They also encourage a programming style that is focused on ownership and borrowing, rather than shared mutable state.
The stack and the heap in Rust
In computer science, the stack and the heap are two different regions of memory that are used for storing data during program execution.
The stack is a region of memory that is used for storing data that has a known size at compile time. It is a contiguous block of memory that is managed by the operating system and is used for storing local variables, function arguments, and return addresses. The stack is a last-in, first-out (LIFO) data structure, which means that the most recently added item is the first one to be removed.
The heap, on the other hand, is a region of memory that is used for storing data that has a size that is not known at compile time. It is a more flexible data structure than the stack and is used for storing dynamically allocated data such as strings, arrays, and objects. The heap is managed by the programmer and is not subject to the same LIFO constraints as the stack.
The main difference between the stack and the heap is that the stack is faster and more efficient than the heap, but it has a limited size and is not as flexible. The heap, on the other hand, is slower and less efficient than the stack, but it can grow or shrink as needed and is more flexible.
In Rust, data types that have a known size at compile time are stored on the stack, while data types with a size that can only be determined at runtime are stored on the heap.
Rust's data types stored on the stack:
Booleans (
bool)Characters (
char)Numeric types (signed and unsigned integers, floating-point numbers)
Pointers (
*const Tand*mut T)References (
&Tand&mut T)Arrays (
[T; N])Tuples (
(T, U, ..))
Data types that are stored on the heap:
Strings (
String)Vectors (
Vec<T>)Hash maps (
HashMap<K, V>)Other dynamically sized data structures
When a value is stored on the stack, it is allocated on a fixed-size block of memory that is automatically deallocated when the variable goes out of scope. When a value is stored on the heap, it is allocated on a variable-size block of memory that must be explicitly deallocated using the drop function or by letting the value go out of scope.

Summing up
Learning Rust can be challenging, especially if you’re new to programming. However, if you’re already familiar with other programming languages, it might be easier for you to grasp some of the concepts.
Rust is a complex and strict programming language that aims to solve some challenging problems in programming. It has a steep learning curve and requires understanding some core concepts around ownership. However, Rust is trying to lower the learning curve through teaching materials and good compiler errors mentioned earlier.
If you’re enthusiastic about Rust, start with Rust.
Learning programming is more about learning programming concepts, from stacks and pointers to closures and macros. A particular programming language would emphasize some concepts and make them easy in its syntax while de-emphasizing other concepts.
Rust is also considered to be a great alternative for C/C++ and offers high performance in addition to helping you eliminate common bugs caused by languages like C++.
So, while might be challenging to learn initially, especially due to its unique features like ownership and borrowing, it can be a rewarding experience once you get the hang of it.
I hope that the more I dive into the deep of Rust, I will be able to share more about this 'not that much scary language'.
Post-article note
A few days after I wrote this article, something happened in my life and career:
I got promoted and moved into the DevOps Team as a Senior DevOps Specialist.
While it was the thing that I wanted to do for some time. It left me with a few new things to learn. Not much, but...
I already worked with Kubernetes, Docker, Containers and CI/CD (Jenkins and Drone or GitLab CI) and IaC (Terraform, Vagrant), but I must admit that I lack knowledge of computer networks area, especially routing, subnets etc.
Apart from networks, there are other new things to learn like more advanced Linux commands and more advanced things about Kubernetes etc. I also lack knowledge in working with one of the major clouds like AZURE, AWS or GCP.
The cloud staff is not a necessity for a moment since we use on-premise stuff rather than the cloud (own VM infrastructure together with own Kubernetes), but as it seems - every DevOps Engineer should have at least a regular level of knowledge in that area.
I also need to level up my knowledge of Python, Ruby and Go in terms of scripting, especially in the DevOps department. Although I am all-wonder, which probably was the cause of moving me to DevOps duties, I might lack a little bit in this particular area and standards.
This forces me to put Rust on the shelve for a while, at least once I am done with DevOps staff.
And to be honest:
Rust is kinda hard for Rubyists and Pythonistas, especially when the developer lacks a little bit of knowledge of C/C++ languages.
Starting my software developer journey from Python in deep-dive mode right into Data Engineering - was a mistake.
Now, I have more to fix, than I would have to learn if I start with C/C++ or Rust.